Why and how we moved exports to Temporal
Sep 26, 2023


- Tomás Farías Santana
![Tomás Farías Santana]()
- Ian Vanagas
![Ian Vanagas]()




On this page
- The trouble with export apps
- 1. Unreliability
- 2. Visibility
- 3. Expense
- Temporal to the rescue
- How we built our new export system with Temporal
- Improving reliability and adding retries
- Making exports transparent (internally and externally)
- Improving performance
- Our new export system
- What’s next?
- Further reading
PostHog aspires to be the single source of truth for our users, but we also believe they should own their data. We don't (yet) fulfill every need, and even if we did, users still want to use their data on other platforms. It's non-negotiable.
That's why we built export apps, which enabled users to own their PostHog data and move it where they liked. These apps supported users for some time, but haven't scaled well as PostHog and our customers have grown. Our solution is the newly upgraded exports system, now in public beta. Built using Temporal, this post covers why and how we made the change, and what we are building next.
The trouble with export apps
Although export apps worked well for smaller customers, larger ones often ran into problems. Exports would frequently fail, error out, or duplicate and drop data. It was frustrating for customers and created an outsized burden on our pipeline team.
Our app service structure was the source of our problem. It worked well for stateless apps, like GeoIP, but our export apps were stateful. They relied on external services that could degrade or fail, requiring timeout and retry logic the existing structure didn't support.
This limitation manifested in three problems:
1. Unreliability
The export manager had no way of reliably detecting whether an export had failed or was simply taking too long, and it eagerly retried after a timeout. This weakness created a cascade of problems.
Retries generated multiple copies of the same export job with the same state, running at the same time. This created a race condition where, whenever a new copy started, it reset the progress to zero, and other copies resumed from the beginning again. This resulted in duplication in the exported data, high infrastructure load, and database locks and conflicts.
Batches also couldn't pause, run simultaneously, or restart from where they left off. They had to run individually from the start. This meant our team often had to manually trigger and manage resets.
2. Visibility
We didn’t have a clear picture of what was happening in the export apps, either. Our codebase had multiple work queues, such as Celery, Kafka, and Graphile, each running in separate contexts without full visibility.
We didn’t have logs or reports for export apps. For example, we didn’t know the amount of exported data or when duplicate runs were happening. When issues arose, we relied on users to tell us. This led to a lot of firefighting and often manual restarts of exports.
3. Expense
Export apps were also expensive for both us and users.
Users had costs not because PostHog charges a lot for exports – we weren’t charging anything – but because they were expensive on the destination side. If your export failed 75% through and needed to reset, you ended up paying ingestion fees of 175% on the destination side.
PostHog also paid for more processing because exports were failing repeatedly.
More importantly to us, export apps were an expensive drain on the pipeline team's time. Our team was spending too much time firefighting and "babysitting" exports. They had to reactively deal with reliability problems, rather than proactively working on performance.
It was obvious we'd outgrown the export apps and needed a reliable, transparent, and cost-effective system if we wanted to scale further.
Temporal to the rescue
Early in 2023, one of our engineers, James Greenhill, opened an RFC recommending using Temporal at PostHog. Temporal is a workflow engine abstracting away the details of failure modes, retry logic, and timeouts. This enables developers to build and deploy rock-solid business logic. It's used by companies like Uber, Coinbase, Doordash, and Hashicorp, which have large data flows.
In Q2, we set a goal of "rock solid-batch processing" and chose Temporal to build it because it helped solve issues like:
- Retry, resume, cancel, and timeout logic per activity and workflow.
- Provides assurances about running exactly-once.
- Visibility into the status of workflows, including errors and logging.
- Scheduling.
Instead of building all this functionality ourselves, Temporal takes care of it for us. After some debate, we felt building a workflow engine would not be a competitive advantage for us. As satisfying as it would be to write, nothing about what we build on Temporal is novel enough to justify an investment into a competing runtime.
How we built our new export system with Temporal
We didn’t completely rebuild our export system; many of the pieces still worked, we just needed to modify them to work with Temporal’s scheduling and execution capabilities. This meant building a batch export abstraction layer on top of Temporal. Specifically, the abstraction layer has three models:
BatchExportDestination: How users configure where to export data and the configuration for that destination.BatchExport: Defines the configuration to export data to a destination, either on a schedule or manually by a backfill. Maps to a Temporal Schedule and contains aBatchExportDestination.BatchExportRun: An instance ofBatchExportfor each triggered workflow. Users aren’t meant to create these, only Temporal. They mostly report on the progress and status of individual workflow executions.
Users create a BatchExport that includes a schedule and a destination (stored as a BatchExportDestination). Temporal then triggers the workflow execution to read data from PostHog, export data to the destination, and return results to the user. You can read a full description of how batch exports work in our docs.
With this structure in place, we began working on improving reliability, transparency, and performance.
Improving reliability and adding retries
We prioritized improving reliability. As mentioned, Temporal supports retry and timeout logic per activity and workflow, which makes a big difference. All we needed was to tune this for our system and destinations. We did this in four main areas:
ClickHouse
- Spaced out retries when reconnecting to prevent failures if in use by another query.
- Retry connection errors which are likely network failures rather than outages.
- Use offline ClickHouse cluster to improve performance and allowable query length.
- Sacrificed some performance to de-duplicate batches by adding the
DISTINCT ONclause because ClickHouse handles de-duplication asynchronously so it isn’t guaranteed at query time.
Postgres
- Health checks to ensure it is healthy before running workflows.
- Retry forever because we control everything related to those activities so failures are transient (other than bugs).
Destinations
- Define which destination errors are retriable and which aren’t. As a rule of thumb: user errors aren't, service errors are.
- Enable migration of old export app
PluginConfigtoBatchExport. Handle old Snowflake export app schema too. - Reset the iterator when a
JSONDecodeErrorhappens to keep the workflow going. - For Snowflake, handle query output error and
ForbiddenError. Add and pass role. - Make our S3 key generation aware of directory separators.
Temporal
- Add max retries and errors so it doesn’t retry forever.
- Add heartbeat API to track activity because we lose state on deployment causing exports to reset.
- Create an endpoint for resetting a
BatchExportRun.
All of this and future improvements are possible because of the framework and services Temporal provides.
Making exports transparent (internally and externally)
The second part of the move to Temporal was making processes transparent both internally and externally.
As mentioned in the last section, Temporal creates transparency into the completions, errors, and latency of workflows. We also track bytes and records exported. These enable us to improve the export system further and faster than the old system.
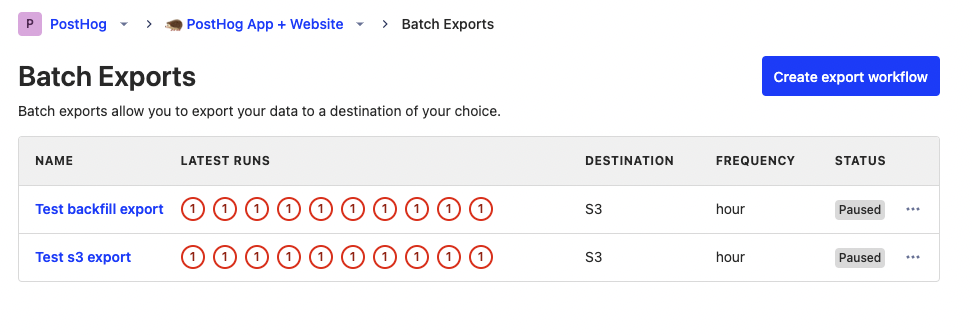
For users, the old system hides runs. Exports now have their own page. On this page, users can:
Configure, start, pause, unpause, reset, edit, and delete exports.
See the status, frequency, destination, and latest runs of each export.
Create historic exports (backfills) using date range.
The work to make exports transparent required us to improve encryption, too. This included:
Adding an encryption codec because Temporal imports aren’t encrypted by default and our inputs can contain credentials.
Changing
BatchExportDestinationsto anEncryptedJSONFieldto ensure no encrypted credentials in the database and no credentials (neither encrypted nor unencrypted) in the logs.Supporting S3 encryption configurations.
Improving performance
Finally, with improved reliability, we can put effort into improving performance. Based on our work so far, we’re confident there are many potential gains here. We know this because we repeatedly bumped up the timeout time or number of retries during development. We learned some exports took longer than initially expected (over 30 minutes).
A big performance gain was implementing our own ClickHouse async client, and then streaming results in Apache Arrow format. This helped us move away from the inefficient JSONEachRow form which takes ClickHouse 25-30 minutes to stream 800k rows (total of 5GB). The same 800k rows stream in 300MB and less than a minute with Apache Arrow.
Other improvements also include running BatchExportRuns simultaneously by scheduling them together and buffering backfills to prevent larger ones from starving all other workflows.
Our new export system
We needed this work for exports to be a first-class feature in PostHog. With this structure in place, we:
- Spend less time spent on firefighting.
- Can focus more on export performance
- Have better visibility into how workflows are failing or lagging and can target solutions to these problems.
Having a reliable, transparent, and performant export system enables us to further improve our customer data platform and warehouse functionality (currently in private beta), which is key for us to succeed in the long term.
What’s next?
As mentioned, we built the structure for BatchExports, a UI, and destinations like Snowflake, S3, and BigQuery, but there’s still a lot to do including:
- More destinations like Postgres and Redshift.
- Improve our webhook system to enable multiple inputs, workflows, and destinations.
- Improve performance through parallelizing and file compression.
- Enable users to define their own schema.
- Support more output formats such as blob storage.
- Filter events from exports.
- Roles-based access control for exports.
You can keep up with our progress and provide feedback on our roadmap in the issues linked or the exports mega issue.
Further reading
- How PostHog built an app server (from MVP to billions of events)
- The modern data stack sucks
- In-depth: ClickHouse vs Snowflake


Subscribe to our newsletter
Product for Engineers
Helping engineers and founders flex their product muscles
We'll share your email with Substack